

Inside this article :
With deep expertise in enterprise infrastructure, I’ve seen teams waste thousands on compute costs by failing to evaluate their instance purchasing strategies effectively. The key mistake isn’t choosing between reserved and spot instances but failing to use both effectively. For those running Kubernetes in the cloud, compute costs are often the largest expense. How you purchase instances on AWS, GCP, or Azure can determine whether your cloud infrastructure is a competitive advantage or a cost center. This guide cuts through the marketing jargon to help you make informed decisions.
Why Instance Purchasing Strategy Matters for Kubernetes
Most teams inherit their instance strategy by accident. They spin up a cluster; AWS or GCP provisioning defaults to on-demand instances, and suddenly 70% of the monthly bill is committed to pricing models chosen for convenience, not optimization.
Kubernetes changes the equation. Unlike traditional VMs that serve a single application, Kubernetes clusters consolidate dozens of workloads with different cost sensitivities. Some applications are time-sensitive and business-critical. Others are batch jobs, off-peak workloads, or fault-tolerant services that can tolerate interruptions.
This heterogeneity is your cost-optimization superpower if you exploit it correctly.
Reserved Instances: Predictable Costs, Committed Capacity
Reserved Instances (RIs) are a commitment contract. You pledge to use a certain capacity for 1 or 3 years, and in return, you pay 40-70% less than on-demand rates. The math is straightforward: if you have a stable, predictable baseline load, RIs deliver significant savings.
When Reserved Instances Make Sense:
Your baseline Kubernetes workloads, monitoring, logging, CI/CD infrastructure, and core APIs rarely disappear. These services run 24/7, with stable, predictable resource requirements. This is where RIs excel. If you know you’ll need 50 vCPUs running continuously, purchasing RIs for that capacity locks in savings immediately.
Most enterprises can reserve 50-70% of their compute capacity without risking unused inventory. The remaining 30-50% stays flexible to handle traffic spikes, new applications, and the unpredictable growth that always happens.
Common Mistakes with Reserved Instances:
Teams often reserve too aggressively, especially early in their cloud adoption. They buy RIs for peak load, not baseline load, then find themselves locked into excess capacity when demand drops. This turns a cost optimization into a financial liability.
Another mistake: failing to align RIs with your actual Kubernetes topology. If you reserve instances in only one availability zone but your cluster spans three, you’re leaving discounts on the table. Or worse, you’ve reserved instance types you’ve since migrated away from.
The solution? Reserve conservatively, monitor utilization, and adjust yearly during renewal cycles.
Spot Instances: Maximizing Batch and Fault-Tolerant Workloads
Spot Instances are the alternative pricing model: use spare cloud provider capacity at 70-90% discounts in exchange for the possibility of interruption. They’re not “unreliable”they’re a different risk profile, appropriate for different workloads.
Kubernetes is built for spot instances. The scheduler can tolerate node failures, pod disruptions are normal, and workload spreading across multiple nodes is the default. This is exactly the environment where spot instances thrive.
Where Spot Instances Shine:
Batch processing, data analytics, testing environments, and stateless service replicas are perfect candidates. If a node is evicted, Kubernetes reschedules the pod to another node. If your application is replicated across 10 pods and one is interrupted, users never notice.
A typical pattern: run your stateless backend services on a mix of reserved and spot instances. Reserved instances provide a baseline of availability, and spot instances absorb traffic spikes at lower cost. When a spot instance is reclaimed, pods are moved to reserved nodes, and availability remains high.
For machine learning training, overnight batch jobs, and periodic ETL processes, spot instances are nearly always the right choice. You’re paying 10-20% of on-demand prices for the same compute power.
The Interruption Question:
Teams often overestimate interruption risk. Spot instance interruption rates vary by region, instance type, and timetypically 5-10% annually for most workloads, though this fluctuates. For a 10-pod deployment with automatic rescheduling, a 10% annual interruption rate on a single pod results in minimal user impact. The cost savings dwarf the operational overhead.
Hybrid Strategy: The Right Approach
The most cost-effective teams don’t choose between reserved and spotthey layer them. Here’s the pattern that works:
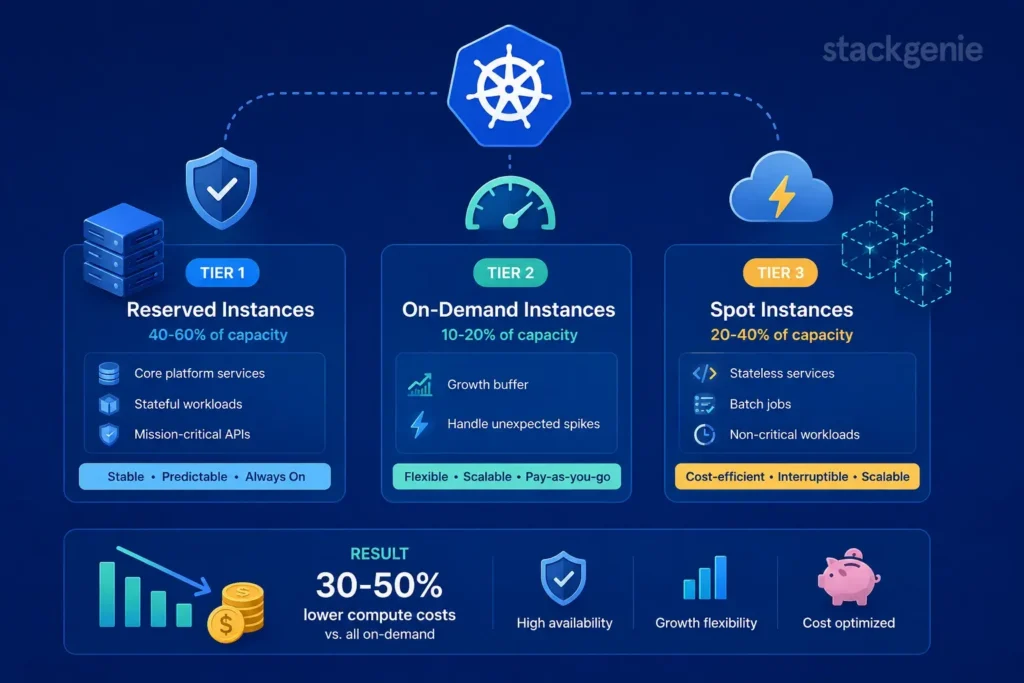
Tier 1: Reserved Instances for Baseline (40-60% of capacity). Core platform services, stateful workloads, and mission-critical APIs run on reserved instances. This guarantees availability and locks in the best unit costs.
Tier 2: On-Demand for Growth Buffer (10-20% of capacity). Keep some on-demand capacity to handle unexpected spikes without the purchase commitment. This is your safety valve.
Tier 3: Spot Instances for Optimization (20-40% of capacity) Stateless services, batch jobs, and non-critical workloads run on spot. As long as you’ve configured Kubernetes for multi-zone deployments and pod disruption budgets, spot instances safely amplify your cost efficiency.
This three-tier approach typically reduces compute costs by 30-50% compared to an all-on-demand approach, while maintaining high availability and growth flexibility.
Regional and Multi-Cloud Considerations
Reserved Instances are regional. You can’t take a US-East RI and use it in Europe. This matters if you’re running multi-region Kubernetes clusters. You’ll need to reserve capacity in each region separately, which complicates the economics.
Spot instance availability also varies by region and cloud provider. AWS spot availability is stable in mature regions (US-East-1, EU-West-1) but unpredictable in newer ones. GCP’s committed discounts offer middle-ground pricing without interruption risk. Azure’s reserved instances work similarly to AWS.
If you’re considering multi-cloud or multi-region Kubernetes, get help modeling the actual cost impacts. The strategy that works for single-region AWS often needs adjustment for GCP + AWS or for clusters spanning continents.
Measuring and Optimizing Your Instance Mix
The strategy only works if you’re actually monitoring it. Most teams have no visibility into instance type mix, reservation utilization, or spot vs. on-demand split. They make purchasing decisions based on guesses.
Proper cost monitoring should show you:
- How much capacity you’re actually using vs. reserved
- Interruption rates and their impact on specific workloads
- Cost per service or team (if using Kubernetes namespaces for cost allocation)
- Opportunity for additional spot instance adoption
Without this visibility, you’re optimizing in the dark.
The Reality Check
I’ll be direct: not every team needs to optimize instance purchasing. If your cloud bill is $2,000 monthly, the overhead of managing reserved and spot instances outweighs the savings. The optimization is most valuable at $20,000+ monthly bills, where you’re talking about real money.
Also, your Kubernetes architecture matters. If you’re still running monoliths on Kubernetes, the resilience assumptions behind spot instances break down. If your cluster spans three regions but your database is single-region, your fault-tolerance story is incomplete regardless of the instance strategy.
Cost optimization isn’t a checkbox; it’s an ongoing commitment to aligning your infrastructure with your actual workload patterns.
Next Steps
Start by establishing baseline cost visibility. Understand your current compute costs, instance mix, and utilization rates. Identify which workloads can tolerate spot instances without degrading performance. Then reserve conservatively and layer in spot instance capacity with proper Kubernetes configuration.
The difference between a well-optimized instance strategy and a default strategy is often $5,000-$50,000+ monthly in savings. That’s engineering budget, headcount, or innovation velocity all things that matter.
If your team needs help designing a cost-optimized Kubernetes infrastructure strategy tailored to your workloads and regional footprint, talk to our Kubernetes and cloud cost optimization specialists. We’ve helped enterprises cut compute costs by 35-50% while improving reliability through proper instance-strategy alignment.
Talk to our Kubernetes and cloud cost optimization specialists?
Contact Us NowFrequently Asked Questions
Q1: What are Reserved Instances?
Reserved Instances are discounted cloud compute commitments that reduce infrastructure costs by up to 70% for predictable workloads.
Q2: What are Spot Instances?
Spot Instances use unused cloud capacity at significantly lower prices but may be interrupted when capacity is reclaimed.
Q3: Which is better for Kubernetes?
Reserved Instances are ideal for stable production workloads, while Spot Instances are best for stateless, batch, and fault-tolerant applications.
Q4: Can Reserved and Spot Instances be used together?
Yes. Most enterprises use a hybrid strategy combining Reserved, Spot, and On-Demand instances to balance cost, availability, and scalability.
Q5: How much money can Reserved and Spot Instances save?
A well-designed hybrid strategy can reduce Kubernetes compute costs by approximately 30–50%, depending on workload characteristics.
Q6: Are Spot Instances reliable for production?
Yes, when used for fault-tolerant Kubernetes workloads with Pod Disruption Budgets, Cluster Autoscaler, and multi-zone deployments.

