
Inside this article :
Internal Developer Platforms (IDPs) promise to accelerate delivery, reduce cognitive load, and bring consistency to cloud-native workflows. Yet many platform initiatives stall after initial excitement. Teams build beautiful portals with sleek dashboards and comprehensive catalogs, only to watch developers return to their custom scripts within weeks.
The problem isn’t the portal. It’s what’s missing underneath.
The Portal Trap: Beautiful Facades Without Foundations
We’ve seen this pattern repeatedly across organizations: platform teams invest months building a developer portal curating service catalogs, designing templates, and crafting documentation. The launch generates buzz. Developers explore the interface, bookmark a few pages, and then quietly go back to their established workflows.
Why? Because clicking through a portal shouldn’t be harder than running a script. When the platform can’t actually execute the work provision infrastructure, configure CI/CD, or wire up observability it becomes a documentation site with extra steps.
Portals serve an important purpose: they provide discovery, visualization, and a unified entry point. But without robust APIs and automation underneath, they’re showrooms without factories. Developers need platforms that move work forward, not just display what’s possible.
API-First: Building Platforms with Muscle
The API-first approach inverts the typical platform-building sequence. Instead of starting with the user interface, you begin with the capabilities the “muscle” that performs actual work.
This means building a service layer that encapsulates:
 Golden Path Workflows: End-to-end orchestration for common developer tasks. Not just generating boilerplate files, but actually creating repositories, configuring CI pipelines, setting up GitOps deployments, and wiring observability all with proper error handling and idempotence.
Golden Path Workflows: End-to-end orchestration for common developer tasks. Not just generating boilerplate files, but actually creating repositories, configuring CI pipelines, setting up GitOps deployments, and wiring observability all with proper error handling and idempotence.
Centralized Policy and Governance: Authentication, authorization, and audit logs in a single enforcement point. When security and compliance requirements live in the API layer, they apply consistently regardless of how developers access the platform through a portal, CLI, or ChatOps.
Self-Service Infrastructure with Guardrails: Developers express intent (“I need a PostgreSQL database for my service”) and the platform translates that into organization-approved infrastructure code with encryption, networking, tagging, and naming conventions already configured.
Integrated Observability: Day-zero telemetry that attaches automatically. The first deployment generates baseline dashboards showing latency, error rates, and throughput without manual configuration.
Transparent Abstractions: Every convenience feature links back to what actually got created and how to override safely when needed. Abstractions help new developers move quickly while providing escape hatches for teams with specialized requirements.
This muscle layer becomes the platform’s core contract. Multiple interfaces portals, CLIs, CI/CD integrations can invoke the same capabilities, ensuring consistency and reducing maintenance burden.
Finding the Balance: Core vs. Periphery
A common question emerges: what belongs in the platform’s core versus what should remain team choice?
Put too much in the platform and you build a cage rigid abstractions that can’t flex when teams need something different. Leave too little and you get chaos every team reinventing pipelines, policies, and infrastructure patterns.
The balance lies in distinguishing core from periphery:
Core (Platform Responsibility):
- Authentication and authorization
- Audit logging and compliance
- Golden paths for common workflows
- Infrastructure provisioning with security baselines
- Observability integration
- Resource naming and tagging conventions
Periphery (Team Choice):
- Application frameworks and languages
- Database selection
- Message broker preferences
- Frontend architectures
The platform ensures consistency where it matters security, compliance, operational standards while preserving autonomy where it doesn’t implementation details that teams understand best for their contexts.
Golden paths represent this balance well: attractive enough that most teams choose them willingly, but with clear exits when justified by specific requirements.
Real-World Implementation: Lessons from the Field
At StackGenie, we’ve guided multiple organizations through platform engineering transformations. One pattern consistently emerges: the temptation to start with the portal.
One client initially focused on Backstage implementation building service catalogs, template libraries, and documentation. Adoption plateaued quickly. The interface looked polished, but the heavy lifting wasn’t automated.
We pivoted to API-first development:
Built a service layer using FastAPI with organization SSO, exposing idempotent endpoints for complete workflows:
- bootstrap_service → creates repository with standardized structure
- configure_ci → sets up CI pipeline with security scanning
- setup_gitops → configures GitOps deployment
- enable_observability → wires telemetry and dashboards
- provision_infrastructure → provisions cloud resources with governance
Centralized policy enforcement: Authorization rules, naming conventions, cost tags, and environment protections enforced in one place. Every action logged for audit.
Template versioning: Every scaffolded service includes metadata tracking which template version and golden path created it, enabling safe upgrades later.
Multiple interfaces, single backend: Both the Backstage plugin and CLI invoke identical endpoints, guaranteeing UI and terminal parity.
The results spoke clearly:
Developer velocity increased because cognitive load decreased. Instead of assembling pipelines, infrastructure code, and observability manually, developers followed golden paths that made secure defaults the easiest choice.
Onboarding time dropped significantly. New engineers went from “waiting on tickets” to “pushing their first PR” in days rather than weeks because access, scaffolding, CI configuration, and dashboards activated in a single flow.
Operational confidence improved because policy, audit, and security controls lived in the muscle layer. Platform and security teams could verify compliance without creating bottlenecks.
Evolution became practical. Adding new golden path capabilities or updating templates happened in the backend and immediately benefited all interfaces. No duplicate maintenance.
Adoption grew organically because the platform earned trust by actually reducing friction.
Getting Started: Your First Slice
Building an API-first platform doesn’t require boiling the ocean. Start with focused iterations:
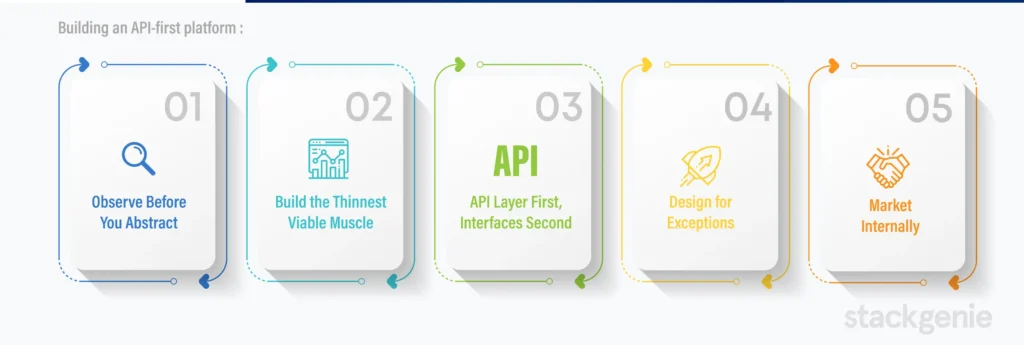
1. Observe Before You Abstract
Shadow your developers. Watch how they actually work the tools they switch between, the waiting periods, the handoffs to other teams. Document the top three friction points as specific jobs-to-be-done.
2. Build the Thinnest Viable Muscle
Choose the most common developer workflow in your organization. For many teams, this is: create service → configure CI → deploy with GitOps → basic observability. Build excellent automation for that single flow before expanding.
3. API Layer First, Interfaces Second
Develop the service layer that actually executes work and enforces policy. Once the capabilities are solid, add the portal and CLI as thin clients that invoke those capabilities. Keep interfaces lightweight so they can evolve independently.
4. Design for Exceptions
Golden paths should be the easiest option, not mandatory. Provide clear mechanisms for teams to override defaults when justified with appropriate review, approval, and logging. Senior developers and architects need configurability within the golden path.
5. Market Internally
Great platforms still need adoption. Run demos, publish release notes highlighting what improved, and celebrate teams that got faster by using the platform. Turn satisfied users into advocates.
Measuring What Matters
Platform success isn’t measured in YAML lines saved or portal clicks generated. What matters is whether teams can deliver with less friction and more safety.
Track a blend of delivery and experience metrics:
Lead Time and Deployment Frequency: How quickly do changes move from commit to production? Can teams deploy more often with confidence? These indicate whether you’ve reduced bottlenecks.
Change Failure Rate and MTTR: Low failure rates combined with fast recovery times (measured in minutes, not hours) show that guardrails are working without blocking flow.
Feedback Loop Speed: The time from code push to test results, build completion, or deployment success. Shorter loops keep developers in flow state rather than context-switching.
Cognitive Load: Qualitative assessment of how many tools, logins, approvals, and steps developers navigate. Lower cognitive load means more focus on delivering value.
Adoption Rate: The strongest signal comes from what teams choose voluntarily. High adoption of golden paths without mandates indicates trust. Conversely, widespread workarounds suggest the platform doesn’t meet real needs.
Combine quantitative metrics with regular developer conversations to understand not just what’s changing but why.
Common Antipatterns to Avoid
Portal-as-Platform: Treating the UI as the heart of the platform rather than a friendly interface to robust capabilities. The real power lies in APIs and automation.
Premature Abstraction: Building abstractions before understanding actual developer workflows often hides the wrong details or blocks critical steps. Observation must precede abstraction.
Gatekeeping in Disguise: If your “golden path” is slower or more cumbersome than workarounds, developers will bypass it. The secure, governed path must also be the fastest path.
Policy by Documentation: Expecting developers to manually follow rules documented in wikis guarantees drift. Embed guardrails directly in templates, workflows, and automation so compliance happens by default.
One-Size-Fits-All Rigidity: Providing no escape hatches for legitimate exceptions creates resentment and shadow IT. Design golden paths that serve 80% of cases while accommodating the other 20% through documented override mechanisms.
The Platform as Product Mindset
An internal developer platform isn’t a collection of tools it’s a product with users who happen to work in the same organization. This perspective fundamentally changes how you approach platform development.
Products require:
- Understanding user needs through observation and feedback
- Iterative development based on real usage patterns
- Marketing and communication to drive adoption
- Support and documentation that meets users where they are
- Evolution based on changing requirements
The API-first approach supports this product mindset by creating a clear separation between capabilities (the muscle) and interfaces (the faces). You can evolve each independently based on user feedback without major rewrites.
Moving Forward
The path to an effective internal developer platform starts with a single principle: build the capabilities before the interface. Create the muscle that actually performs work, enforces policy, and reduces friction. Then provide multiple ways to access those capabilities—portal, CLI, API integrations—letting teams choose what fits their workflow.
This approach transforms platforms from showcases into accelerators. Developers adopt them not because of mandates but because the platform genuinely makes their work easier and safer.
Start small. Pick one workflow that causes frequent friction. Build excellent automation for that workflow with proper auth, audit, and governance. Deploy it with both a portal interface and a CLI. Measure adoption and feedback. Iterate.
Everything good flows from that first well-executed slice.
At StackGenie, we help organizations build cloud-native platforms that developers actually want to use. Our platform engineering consulting combines deep Kubernetes expertise with product thinking to create IDPs that scale with your teams. Connect with our platform engineers to discuss your platform journey.

